

今まで『Stable Diffusion web UI』を触ってきて、一番衝撃を受けました。
それは、『Realistic Vision V2.0』というモデルに出会ったからです。
ほんとこのモデルはすごい。
「Civitai」のサイトで「Realistic Vision V2.0」と検索するとイケオジの写真(のようなイラスト)と一緒に出てくるモデルです(要無料登録)。
※このサイトでは、あまり青少年向けじゃない画像も出てくるので注意
正直なめてました。
どうせエ〇とか有名人の似顔絵的な写真画像に特化してるんじゃないかと。
実際に使ってみるとそんなものじゃなかったです。
これを使うと
写真と見紛うような美麗なイラストが簡単に作れます。
事例紹介
一例として、「landscape」(風景)と、あとちょっと呪文(すべてのイラストで共通、後述)を入れて生成してみます。
まず最初に行っておくと、自分のPCだと高品質化(ハイレゾ編集)をするとPCへの負荷が厳しいので、今回はハイレゾ処理なし。
PCスペックに余裕のある方なら、もっと高品質の画像が作れると思います。
または、PCに詳しいのであれば、Google Colab などを使い、自宅のPCスペックに依存せずに快適環境で画像生成も可能です。
自分もそのうちGoogle Colab 環境を作ってみようと思っています。

導入手順は(現在のバージョンだと)ちょっと複雑ですが、できるだけ詳細に書いたつもりです。
「Stable Diffusion web UI」のバージョンによっては記事よりも簡単になってるかもしれません。
「landscape」(風景)のお題で出力された画像がこちら




この間1分弱。
ここで「綺麗だけど、代わり映えしないかな?」と思う人もいるかもしれません。
しかしこれはあくまで「landscape」(風景)というアバウトな指定をしたから、一般的に思い浮かびやすい画像が作られただけです。
いくつか指定をしてみましょう。
Aurora

街並みのオマケ付き
flower garden

ほぼ写真
fishes in the sea

広角のボケまで再現するとは…
space

たった1ワードに詰め込まれてる幻想風景
Scenery that does not exist in reality(現実にない風景)

実際に条件にあってるかはわかりませんが、こういう風変わりな方法で面白い景色を探すことも。
fantasy

ここまでアバウトだと、完全に「お題」。
dragon Versus dragon

もうなんでもアリかな?という感じに(笑)
ここまで、たった一言+定型文をいれただけで自動生成されていると考えると、このすごさが伝わるでしょうか?
また、seed値をランダム(-1)にしておくと、呼び出すたびに出力される絵は変化します。
著作権(肖像権)に関する問題
腰を折って申し訳ありません。
横道にそれてしまいますが、画像生成AIに関わる人は避けては通れない問題だと思うので、ここで挙げさせてもらいます。
この章で記載することは、あくまで私個人の見解であり、記事現在と閲覧してる時期での大きな差異が発生する可能性もあります。
また、私自身は法律の専門家ではありません。
最終的にはご覧になってる方が個々人で判断していただくようお願いします。
画像生成AIがもつ著作権(肖像権)問題は大きく3つに分かれます。
AIが学習に利用した著作物の問題
画像生成AIの生成には既存の著作物(誰かが取った写真、書いた絵など)が使用されています。
これを元に作成すること自体は基本的には問題はないと考えられています。
例えば人間の漫画家でも、有名な先生のアシスタントから出発した方は絵柄は元々の修行時代の先生と似通ってきますよね。
それでも「盗作」等と言われることはありません。
つまり人間でも、何かしらから影響され(学習し)、自分のオリジナルを作り出してるわけで、それと同じことが画像生成AIにも使われているのであれば問題ないだろう、という論があります。
ただ、これは引用の程度の問題もあり、例えば90%近く引用してしまったらそれはやっぱりダメなわけです。
先の漫画家の例でも「トレース疑惑」というのがありますが、ここまでやってしまうと社会的には認められなくなってしまいます。
じゃあ画像生成AIが一つの作品から何%使うのはいいのか?
と言われると引用割合の計測すらできないのが現状です。
そもそも、画像生成AIの学習元には、他の画像生成AIの生成物もあるわけで、こうなると元を辿ることは不可能です。
これに関してはかなりナイーブな問題で、特に画像生成AIに関しては法律の異なる国を跨いだ問題でもあるので結論がでるかどうかもわかりません。
となると、グレーゾーンが長く続く気がします。
AIが作成(出力)した画像の著作権に関する問題
ようは、「あなた」がこの機能で作った画像の著作権を「あなた」が持つかどうかです。
これに関しては日本ではまだ法整備がされていません。
一方アメリカでは、「AIのみで生成した作品には著作権は認めない」という判例があるようです。
ただし、出力された映像を一部手動で変更した場合、変更部分には著作権が発生する=作品全体としても実質的に著作権を含有する。
という論がアメリカでありますので、今後の方向性の一つになる可能性はあります。
ちなみに私が今回載せた画像は100%AI出力となります。
今後、AI画像生成をつかったイラスト(疑似写真含む)を観る機会は加速度的に増えていくことでしょう。
日本でもきちんとした法整備が必要だと思います。
AIが作成のモチーフとした対象の著作権・肖像権の問題
アニメ、ゲーム映像であれば二次創作の範囲でグレーゾーンになる可能性はあります。
前提としてこれらのキャラクターは著作権(若しくは商標権)で保護されますが、その作成者がある程度は黙認してくれてる状況です。
あくまで費用対効果を考えた黙認ですが、日本では「コミックマーケット」という二次創作をメインとしたイベントがニュースで取り上げられるくらいなので、二次創作に関してはグレーゾーンという表現をしました。
現実の人物に対して使った場合は、誹謗中傷や名誉棄損にも発展する可能性もあるので利用は控えた方が良いでしょう。
ただ、肖像権の範囲自体がかなり複雑です。
「織田信長」などの歴史上の人物は肖像権はない、というのは聞いたことはありますが、俳優はどうなんでしょうか?
少なくとも名誉棄損などの対象にはなると思いますので、使わないほうが賢明だと思いますが。
上の3つの論点を見てもお分かりの通り、ほとんどの点で明確な法整備がされていない分野です。
AI画像生成に携わっていく方は、この辺りに注視していく必要があるでしょう。
画像作成までの道筋(各種設定まで)
もしかしたら知らずに来てる方もいるかもしれないので言っておきますと、『Stable Diffusion web UI』と呼ばれるAIによる画像生成機能を使っています。
完全無料で使うことが出来ます。
前提として、一定以上のスペックのPCか、Google Colab等に『Stable Diffusion web UI』をインストールする必要がありますが、今回はローカル環境での動作を想定しています。
ある程度慣れたら「google colaboratory」を使ったweb環境の構築をしてみるといいでしょう。
こちらをすることで、無料でもVRAM16Gの動作環境を入手できます。
VRAM8G以上、できれば12G以上のビデオカード(GPU)があるPC。
VRAMの数値はかなり重要です。
HDDは1T以上は欲しいです、もちろん多ければ多いほどいいですが、SSDである必要はありません。
CPUは多分そこまで必要ないですが、「ミドルスペック」と呼ばれてるものかそれ以上があるといいです。
ちなみに私が使用しているのは「GeForce RTX 3060 Ti VRAM8G」というビデオカードですが、趣味で遊ぶくらいならこれくらいでもなんとか(高画質化のハイレゾ処理で失敗することはある)。
バリバリ『Stable Diffusion web UI』を使いたいのであれば、もう少し上のGPUは欲しいところです。
① 『Stable Diffusion web UI』をインストール
一応以前自分が初めて導入したときの記事は以下。
と言ってもyoutubeで解説動画を出してくれてる人がいたのでその通りにしただけです。
おそらく動画と私の記事を観れば問題なく導入できると思います。
説明すると長くなるので、ここは省略させてもらいます。
②モデル(Realistic Vision V2.0)を導入
最初にもいいましたが、ちょっとアレな表現もあるページなのでリンクは避けます。
流れとしては
・Civitaiをグーグル検索
・Civitaiに登録(無料)
・CivitaiでRealistic Vision V2.0を検索
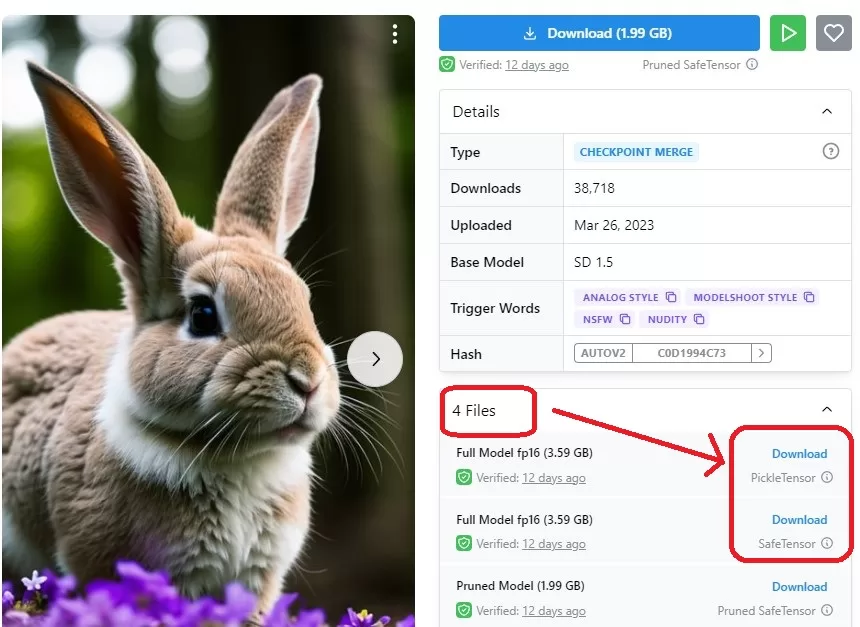
1.99GBのdownloadボタンが目に入ってきますが、4filesのアコーディオンを開くと、3.59GBのバージョンが出てくるので、そちらをダウンロードして下記フォルダに配置。

③ VAE導入
①で導入したものと同じです(動画の通りやっていれば入れてるはず)。
一応説明しておくと、こちらのページから[vae-ft-mse-840000-ema-pruned.safetensors]をダウンロードして、下記フォルダに格納して下さい。
※インストールフォルダの位置によって上の方のフォルダ構成は個々人で異なります。

④ 『Stable Diffusion web UI』を立ち上げてからの設定
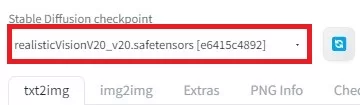
[txt2img]タグで、Stable Diffusion checkpoint設定
realisticVisionV20_v20.safetensorsがあると思うので、それを選択して下さい。
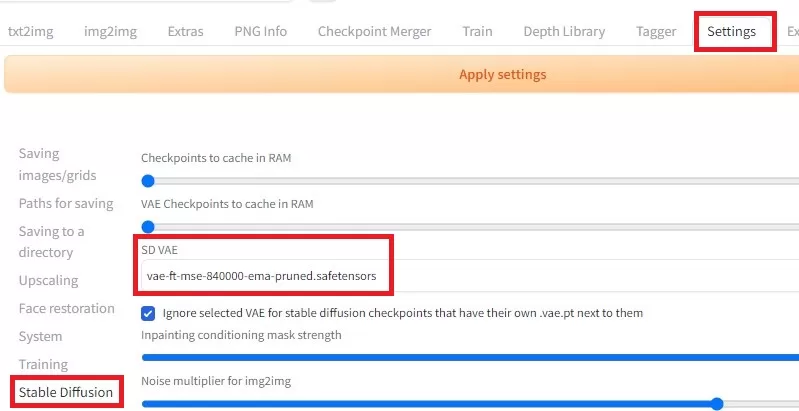
VAE設定
SETTING⇒Stable Diffusion SD VAEがあるので、先ほどVAEフォルダにいれた[vae-ft-mse-840000-ema-pruned.safetensors]を選択します。
EasyNegativeの導入
「EasyNegative」というネガティブpromptを使うのに必要です。
なんのこっちゃ?かもしれませんが、入れておくと少しだけ画質が良くなると思ってください。
配布サイト(Hugging Face)のEasyNegative.safetensorsをダウンロードして、「stable diffusion web UI」インストールフォルダ直下のembeddingsフォルダの下に置いてください。
※インストールフォルダの位置によって上の方のフォルダ構成は個々人で異なります。
ここまでやれば、設定は完了です。
prompt(呪文)の作成と、Generate(生成)
prompt作成
txt2imgのタグに移ると、2つのテキスト入力エリアがあります。
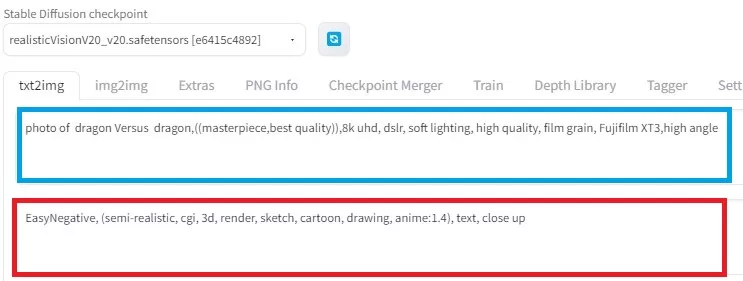
上が、(優先)promptで、生成に使ってほしいキーワードを記述するエリア。
下が、ネガティブpromptで、生成に使わないで欲しいキーワードを記述するエリアです。
と言っても今回は記述する内容だけコピーしておけばOKです。
優先prompt
photo of XXXX,((masterpiece,best quality)),8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3,high angleコピペした後に、XXXXは好きに記述を変更して下さい。
例えば上の画像では「dragon Versus dragon」を入れています。
ここのキーワードに合った画像が生成されます。
最初に紹介したワードはすべてこの記述に使ったワードになっています。
上の記述内容のうち、soft lightingだけは暗めの画像を作成したい場合は抜いてください。
ネガティブprompt
EasyNegative, (semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close upこちらは、基本的に触らなくていいので、そのままコピペして下さい。
ただ、登場して欲しくない要素(例えば「海」とか「山」とか)があれば追加してもいいです。
その他の設定
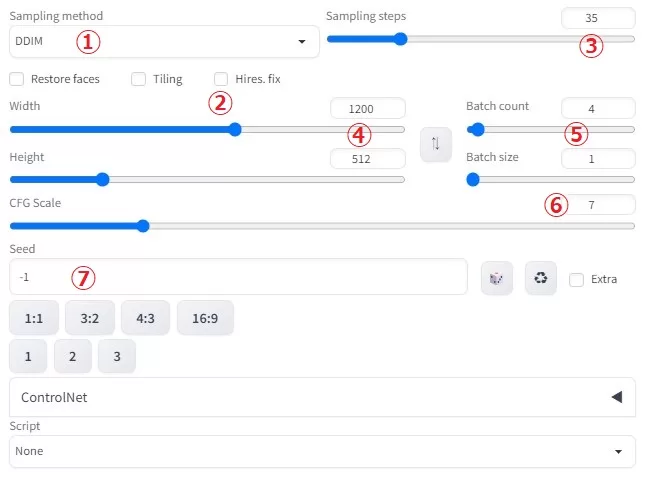
① sampling method
絵柄に影響を与えます。
どれが良いというのは不明ですが、aやSDE等がついてるのは個人的には避けた方が良いと思います。
私はしばらくDDIMをメインに、サブとしてDPM++2M Karrasを使っています(風景画の場合)。
② 今回のケースで必要になるのは、一番右の「Hires.fix」
チェックを入れると書き込みが格段に繊細になります。
絵柄にも影響を与え、人物画の場合は幼いキャラは敢えてチェックを外した方が良い場合もあります。
Upscalerは主にSwinIR_4Xを自分は使っていますが今回は未使用です。
GPUに余裕がある方はチェックを入れておくことをオススメします。
③Sampring steps数を増やすと書き込みが繊細になります。
最低20くらいあった方がいいですが、30でもそこまで変わりません。
40以降はほとんど変わらないと言われています。
Hires.fixの方が効果は目に見えて大きいです。
④解像度(幅×高さ)
出力ファイルの解像度です。
人物画の場合は512×512が適正と言われていますが、今回は1200×512で作成しました。
解像度の縦長/横長でも生成される画像が変わりますので試してみましょう。
風景画は横長か正方形、人物画は正方形か縦長がオススメです。
⑤Batch count(何回試行するか)/Batch size(一回で何枚試行するか)
双方の乗算枚数だけ画像が生成されます。
沢山一気に作りたい場合は使ってもいいですが、PCへの負荷も発生します。
Batch countの方は上げても問題ないといわれていますが、実際のところはよくわかりません。
⑥CFG Scale
Promptの強制力を示す。デフォルトで問題ないです。
⑦Seed
他の条件が同じでも、Seedが違うと全く違う絵が出力されます。
逆に言うと、Seed含めた条件が同じであれば、ほぼ同じ絵が出力されます。
-1はランダムなので、基本は-1でOK。
同じSeedで色々promptをいじりたい場合は固定して試行します。
ControlNetはキャラクターのポーズを制御するツールなので風景画には不要だと思います。
Extraチェックでさらに詳細の設定ができますが、今回は省略します。
Generate(生成)
右のGenerateボタンを押すだけです。
生成速度はPC(GPU)に依存しますが、ハイレゾなしなら数秒~数十秒程度だと思います。
生成したファイルに関しては下記のフォルダーに格納されます。
最後に
「Realistic Vision V2.0」のすごさは伝わったでしょうか?
じつはこのモデルは、風景画だけではなく、リアルなものなら大抵のものは対応できる点がまたすごい。
公式に投稿されてるものをみると、版権物なども多いので注意は必要ですが。
上でリアルなドラゴンの絵を扱いましたが、もちろん他の実在の動物も得意です。

これは今回の風景用のpromtではないですが、「Realistic Vision V2.0」公式ページに投稿されていた(気に入った動物用の)promptの「猫」を「リス」に1単語だけ変更しただけのpromptです。
「猫」を「鳥」に変えると

これはちょっと失敗(笑)
ネコとフクロウのあいの子の新生物になってしまいましたね。
きちんと呪文(prompt)を解析せずに使うとこうなっちゃうことも。
たった1単語変えただけでもかなり変化があるのが分かりますね。
このように、元あるpromptを少し変えるだけで「新しいイラスト」を生み出せるというのがすごいところだと思います。
今回の風景画のpromptに関しては
photo of XXXX,((masterpiece,best quality)),8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3,high angleXXXXの部分を変えればいいです、と申し上げましたが、実際は他にもいろいろ手を加えることでさらに魅力的な絵にすることも可能です。
例えば、high angleを別にアングルに変えたり、 soft lightingを別の要素に変えたり、要素自体を追加してみるのも面白いです。
もちろんそれで失敗してヘンテコな絵になることもありますが、それも含めて『Stable Diffusion web UI』を楽しんでもらえれば幸いです。
あと、今回は使わなかった「Hires.fix」にチェックマークを入れてみるのもオススメです。
もし『Stable Diffusion web UI』を本格的に始めたら、私が作ったprompt管理ツールも使ってやってください。
ただテキストをいじってるだけのツールですが、自分が作ったpromptを記憶しておいたり、一部を変えてみる場合に楽にprompt文を構成できます。
結構便利だと思うのですが、自分だけしか使ってないと寂しいので(笑)

コメント